 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLongLive-2.0: An NVFP4 Parallel Infrastructure for Long Video Generation
May 19, 2026We present LongLive-2.0, an NVFP4-based parallel infrastructure throughout the full training and inference workflow of long video generation, addressing speed and memory bottlenecks. For training, we introduce sequence-parallel autoregressive (AR) training, instantiated as Balanced SP, which co-designs the efficient teacher-forcing layout with SP execution by pairing clean-history and noisy-target temporal chunks on each rank, enabling a natural teacher-forcing mask with SP-aware chunked VAE encoding. Combined with NVFP4 precision, it reduces GPU memory cost and accelerates GEMM computation during training, the proportion of which increases as video length grows. Moreover, we show that a high-quality infrastructure and dataset enable a remarkably clean training pipeline. Unlike existing Self-Forcing series methods that rely on ODE initialization and subsequent distribution matching distillation (DMD), LongLive-2.0 directly tunes a diffusion model into a long, multi-shot, interactive auto-regressive (AR) diffusion model. It can be further converted to real-time generation (4 to 2 denoising steps) with standalone LoRA weights. For inference on Blackwell GPUs, we enable W4A4 NVFP4 inference, quantize KV cache into NVFP4 for memory savings, and boost end-to-end throughput with asynchronous streaming VAE decoding. On non-Blackwell GPU architectures, we deploy SP inference to match the speed on Blackwell GPUs, while the quantized KV cache can lower inter-GPU communication of SP. Experiments show up to 2.15x speedup in training, and 1.84x in inference. LongLive-2.0-5B achieves 45.7 FPS inference while attaining strong performance on benchmarks. To our knowledge, LongLive-2.0 is the first NVFP4 training and inference system for long video generation.
Awaking Spatial Intelligence in Unified Multimodal Understanding and Generation
May 05, 2026We present JoyAI-Image, a unified multimodal foundation model for visual understanding, text-to-image generation, and instruction-guided image editing. JoyAI-Image couples a spatially enhanced Multimodal Large Language Model (MLLM) with a Multimodal Diffusion Transformer (MMDiT), allowing perception and generation to interact through a shared multimodal interface. Around this architecture, we build a scalable training recipe that combines unified instruction tuning, long-text rendering supervision, spatially grounded data, and both general and spatial editing signals. This design gives the model broad multimodal capability while strengthening geometry-aware reasoning and controllable visual synthesis. Experiments across understanding, generation, long-text rendering, and editing benchmarks show that JoyAI-Image achieves state-of-the-art or highly competitive performance. More importantly, the bidirectional loop between enhanced understanding, controllable spatial editing, and novel-view-assisted reasoning enables the model to move beyond general visual competence toward stronger spatial intelligence. These results suggest a promising path for unified visual models in downstream applications such as vision-language-action systems and world models.
SpatialEdit: Benchmarking Fine-Grained Image Spatial Editing
Apr 06, 2026Image spatial editing performs geometry-driven transformations, allowing precise control over object layout and camera viewpoints. Current models are insufficient for fine-grained spatial manipulations, motivating a dedicated assessment suite. Our contributions are listed: (i) We introduce SpatialEdit-Bench, a complete benchmark that evaluates spatial editing by jointly measuring perceptual plausibility and geometric fidelity via viewpoint reconstruction and framing analysis. (ii) To address the data bottleneck for scalable training, we construct SpatialEdit-500k, a synthetic dataset generated with a controllable Blender pipeline that renders objects across diverse backgrounds and systematic camera trajectories, providing precise ground-truth transformations for both object- and camera-centric operations. (iii) Building on this data, we develop SpatialEdit-16B, a baseline model for fine-grained spatial editing. Our method achieves competitive performance on general editing while substantially outperforming prior methods on spatial manipulation tasks. All resources will be made public at https://github.com/EasonXiao-888/SpatialEdit.
PixCLIP: Achieving Fine-grained Visual Language Understanding via Any-granularity Pixel-Text Alignment Learning
Nov 06, 2025While the Contrastive Language-Image Pretraining(CLIP) model has achieved remarkable success in a variety of downstream vison language understanding tasks, enhancing its capability for fine-grained image-text alignment remains an active research focus. To this end, most existing works adopt the strategy of explicitly increasing the granularity of visual information processing, e.g., incorporating visual prompts to guide the model focus on specific local regions within the image. Meanwhile, researches on Multimodal Large Language Models(MLLMs) have demonstrated that training with long and detailed textual descriptions can effectively improve the model's fine-grained vision-language alignment. However, the inherent token length limitation of CLIP's text encoder fundamentally limits CLIP to process more granular textual information embedded in long text sequences. To synergistically leverage the advantages of enhancing both visual and textual content processing granularity, we propose PixCLIP, a novel framework designed to concurrently accommodate visual prompt inputs and process lengthy textual descriptions. Specifically, we first establish an automated annotation pipeline capable of generating pixel-level localized, long-form textual descriptions for images. Utilizing this pipeline, we construct LongGRIT, a high-quality dataset comprising nearly 1.5 million samples. Secondly, we replace CLIP's original text encoder with the LLM and propose a three-branch pixel-text alignment learning framework, facilitating fine-grained alignment between image regions and corresponding textual descriptions at arbitrary granularity. Experiments demonstrate that PixCLIP showcases breakthroughs in pixel-level interaction and handling long-form texts, achieving state-of-the-art performance.
LongLive: Real-time Interactive Long Video Generation
Sep 26, 2025We present LongLive, a frame-level autoregressive (AR) framework for real-time and interactive long video generation. Long video generation presents challenges in both efficiency and quality. Diffusion and Diffusion-Forcing models can produce high-quality videos but suffer from low efficiency due to bidirectional attention. Causal attention AR models support KV caching for faster inference, but often degrade in quality on long videos due to memory challenges during long-video training. In addition, beyond static prompt-based generation, interactive capabilities, such as streaming prompt inputs, are critical for dynamic content creation, enabling users to guide narratives in real time. This interactive requirement significantly increases complexity, especially in ensuring visual consistency and semantic coherence during prompt transitions. To address these challenges, LongLive adopts a causal, frame-level AR design that integrates a KV-recache mechanism that refreshes cached states with new prompts for smooth, adherent switches; streaming long tuning to enable long video training and to align training and inference (train-long-test-long); and short window attention paired with a frame-level attention sink, shorten as frame sink, preserving long-range consistency while enabling faster generation. With these key designs, LongLive fine-tunes a 1.3B-parameter short-clip model to minute-long generation in just 32 GPU-days. At inference, LongLive sustains 20.7 FPS on a single NVIDIA H100, achieves strong performance on VBench in both short and long videos. LongLive supports up to 240-second videos on a single H100 GPU. LongLive further supports INT8-quantized inference with only marginal quality loss.
Accelerating Parallel Diffusion Model Serving with Residual Compression
Jul 23, 2025Diffusion models produce realistic images and videos but require substantial computational resources, necessitating multi-accelerator parallelism for real-time deployment. However, parallel inference introduces significant communication overhead from exchanging large activations between devices, limiting efficiency and scalability. We present CompactFusion, a compression framework that significantly reduces communication while preserving generation quality. Our key observation is that diffusion activations exhibit strong temporal redundancy-adjacent steps produce highly similar activations, saturating bandwidth with near-duplicate data carrying little new information. To address this inefficiency, we seek a more compact representation that encodes only the essential information. CompactFusion achieves this via Residual Compression that transmits only compressed residuals (step-wise activation differences). Based on empirical analysis and theoretical justification, we show that it effectively removes redundant data, enabling substantial data reduction while maintaining high fidelity. We also integrate lightweight error feedback to prevent error accumulation. CompactFusion establishes a new paradigm for parallel diffusion inference, delivering lower latency and significantly higher generation quality than prior methods. On 4xL20, it achieves 3.0x speedup while greatly improving fidelity. It also uniquely supports communication-heavy strategies like sequence parallelism on slow networks, achieving 6.7x speedup over prior overlap-based method. CompactFusion applies broadly across diffusion models and parallel settings, and integrates easily without requiring pipeline rework. Portable implementation demonstrated on xDiT is publicly available at https://github.com/Cobalt-27/CompactFusion
LoRA-Gen: Specializing Large Language Model via Online LoRA Generation
Jun 13, 2025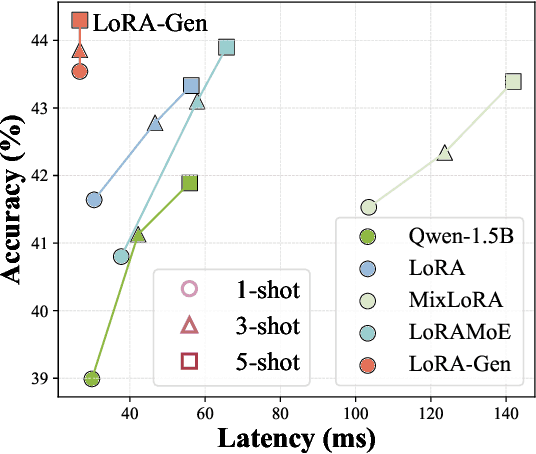

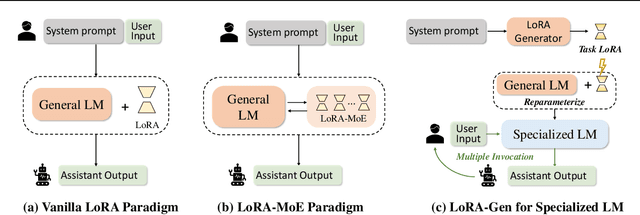
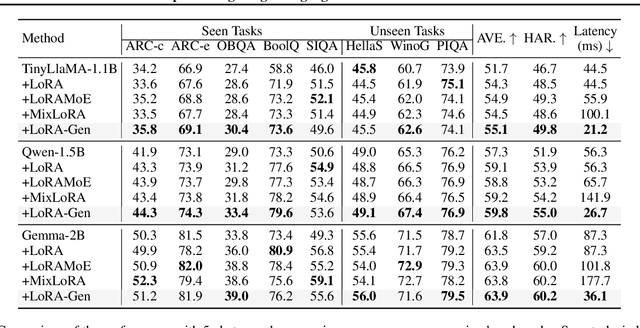
Recent advances have highlighted the benefits of scaling language models to enhance performance across a wide range of NLP tasks. However, these approaches still face limitations in effectiveness and efficiency when applied to domain-specific tasks, particularly for small edge-side models. We propose the LoRA-Gen framework, which utilizes a large cloud-side model to generate LoRA parameters for edge-side models based on task descriptions. By employing the reparameterization technique, we merge the LoRA parameters into the edge-side model to achieve flexible specialization. Our method facilitates knowledge transfer between models while significantly improving the inference efficiency of the specialized model by reducing the input context length. Without specialized training, LoRA-Gen outperforms conventional LoRA fine-tuning, which achieves competitive accuracy and a 2.1x speedup with TinyLLaMA-1.1B in reasoning tasks. Besides, our method delivers a compression ratio of 10.1x with Gemma-2B on intelligent agent tasks.
SAM-R1: Leveraging SAM for Reward Feedback in Multimodal Segmentation via Reinforcement Learning
May 28, 2025Leveraging multimodal large models for image segmentation has become a prominent research direction. However, existing approaches typically rely heavily on manually annotated datasets that include explicit reasoning processes, which are costly and time-consuming to produce. Recent advances suggest that reinforcement learning (RL) can endow large models with reasoning capabilities without requiring such reasoning-annotated data. In this paper, we propose SAM-R1, a novel framework that enables multimodal large models to perform fine-grained reasoning in image understanding tasks. Our approach is the first to incorporate fine-grained segmentation settings during the training of multimodal reasoning models. By integrating task-specific, fine-grained rewards with a tailored optimization objective, we further enhance the model's reasoning and segmentation alignment. We also leverage the Segment Anything Model (SAM) as a strong and flexible reward provider to guide the learning process. With only 3k training samples, SAM-R1 achieves strong performance across multiple benchmarks, demonstrating the effectiveness of reinforcement learning in equipping multimodal models with segmentation-oriented reasoning capabilities.
TensorAR: Refinement is All You Need in Autoregressive Image Generation
May 22, 2025



Autoregressive (AR) image generators offer a language-model-friendly approach to image generation by predicting discrete image tokens in a causal sequence. However, unlike diffusion models, AR models lack a mechanism to refine previous predictions, limiting their generation quality. In this paper, we introduce TensorAR, a new AR paradigm that reformulates image generation from next-token prediction to next-tensor prediction. By generating overlapping windows of image patches (tensors) in a sliding fashion, TensorAR enables iterative refinement of previously generated content. To prevent information leakage during training, we propose a discrete tensor noising scheme, which perturbs input tokens via codebook-indexed noise. TensorAR is implemented as a plug-and-play module compatible with existing AR models. Extensive experiments on LlamaGEN, Open-MAGVIT2, and RAR demonstrate that TensorAR significantly improves the generation performance of autoregressive models.
MindOmni: Unleashing Reasoning Generation in Vision Language Models with RGPO
May 19, 2025



Recent text-to-image systems face limitations in handling multimodal inputs and complex reasoning tasks. We introduce MindOmni, a unified multimodal large language model that addresses these challenges by incorporating reasoning generation through reinforcement learning. MindOmni leverages a three-phase training strategy: i) design of a unified vision language model with a decoder-only diffusion module, ii) supervised fine-tuning with Chain-of-Thought (CoT) instruction data, and iii) our proposed Reasoning Generation Policy Optimization (RGPO) algorithm, utilizing multimodal feedback to effectively guide policy updates. Experimental results demonstrate that MindOmni outperforms existing models, achieving impressive performance on both understanding and generation benchmarks, meanwhile showcasing advanced fine-grained reasoning generation capabilities, especially with mathematical reasoning instruction. All codes will be made public at \href{https://github.com/EasonXiao-888/MindOmni}{https://github.com/EasonXiao-888/MindOmni}.